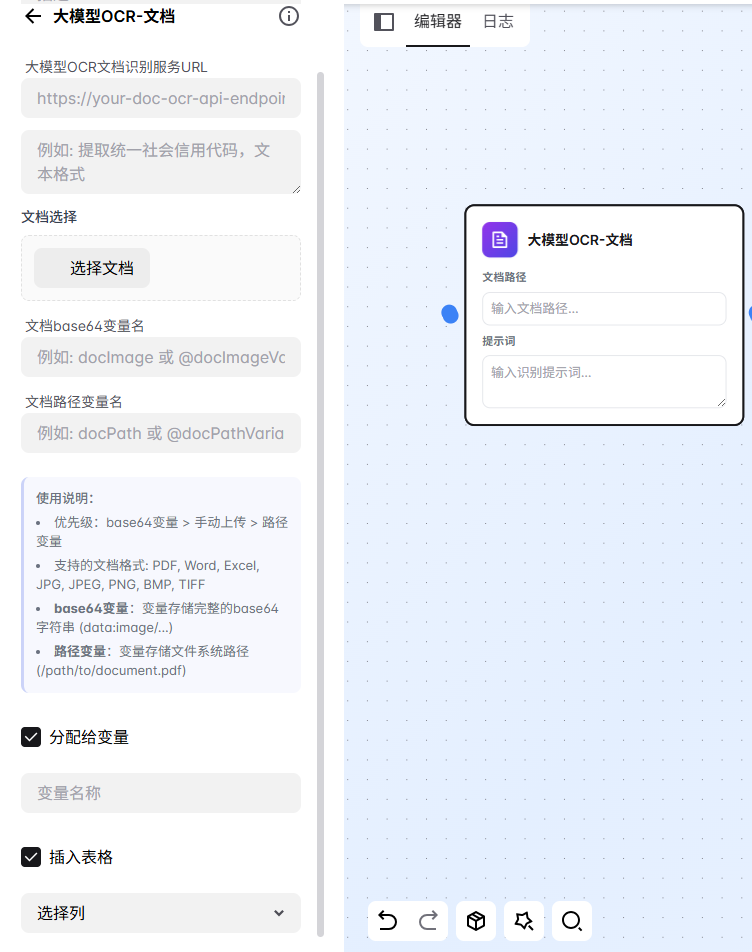
Appearance
大模型OCR-文档
组件概述
大模型OCR-文档组件利用先进的大语言模型技术,对各类文档进行智能识别和信息提取,支持从复杂文档中提取结构化数据。
配置说明
大模型OCR文档识别服务URL
- 作用:指定大模型OCR文档识别服务的API接口地址
- 示例:
https://your-doc-ocr-api-endpoint.com
提示词
- 功能:提示提取特定信息和以什么格式返回信息
- 示例:
提取统一社会信用代码,文本格式
文档选择
提供多种方式指定需要识别的文档源:
选择文档
- 功能:手动上传本地文档文件进行识别
- 支持格式:PDF、Word、Excel、JPG、JPEG、PNG、BMP、TIFF
文档base64变量名
- 功能:通过变量传递base64编码的文档数据
- 格式要求:完整的base64字符串(包含
data:...前缀) - 示例:
docImage或@docImageVc
文档路径变量名
- 功能:通过变量传递文档文件系统路径
- 格式要求:有效的本地文件路径
- 示例:
docPath或@docPathVaria
使用优先级
系统按以下顺序选择文档源:
- base64变量(最高优先级)
- 手动上传
- 路径变量(最低优先级)
数据输出
分配给变量
将识别出的文档内容保存到变量中
- 变量名称:指定存储识别结果的变量名称
插入表格
将识别结果插入到表中
- 选择列:指定插入识别结果的表格列
技术特性
- 基于大语言模型,理解文档上下文语义
- 支持多种文档格式,包括可编辑和扫描文档
- 能够提取结构化信息,如统一社会信用代码等特定字段
- 处理复杂版式和表格数据
应用场景
- 企业资质证件信息提取
- 合同关键条款识别
- 财务报表数据采集
- 证件照文字信息识别
注意事项
- 确保OCR服务可用且网络连接正常
- 文档清晰度直接影响识别准确率
- 复杂版式文档可能需要更长的处理时间
- 建议对关键信息进行人工复核